写在前面
本篇记录Hadoop实战学习中的笔记以及问题分析。
Mapreduce 实战
Mapreduce 程序模型
什么是Mapreduce
MapReduce是一种可用于数据处理的编程模型,我们现在设想一个场景,你接到一个任务,任务是:挖掘分析我国气象中心近年来的数据日志,该数据日志大小有3T,让你分析计算出每一年的最高气温,如果你现在只有一台计算机,如何处理呢?我想你应该会读取这些数据,并且将读取到的数据与目前的最大气温值进行比较。比较完所有的数据之后就可以得出最高气温了。不过以我们的经验都知道要处理这么多数据肯定是非常耗时的。
如果我现在给你三台机器,你会如何处理呢?你应该想到了:最好的处理方式是将这些数据切分成三块,然后分别计算处理这些数据(Map),处理完毕之后发送到一台机器上进行合并(merge),再计算合并之后的数据,归纳(reduce)并输出。
这就是一个比较完整的MapReduce的过程了。
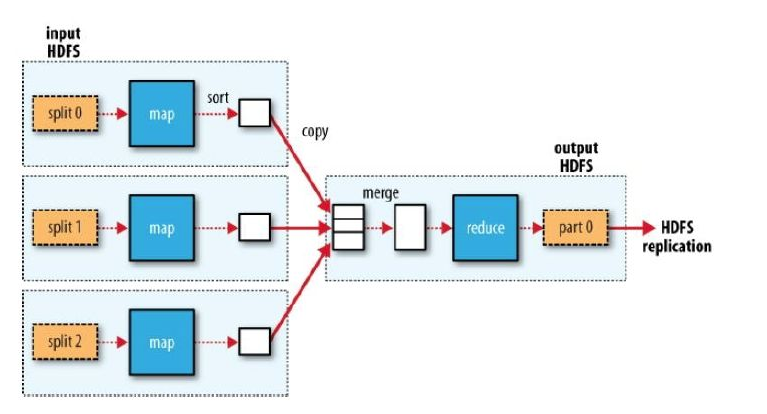
Mapreduce程序结构(以Word Count为例)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
| import java.io.IOException;
import java.util.StringTokenizer;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<LongWritable, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
String inputfile = "/usr/input";
String outputFile = "/usr/output";
FileInputFormat.addInputPath(job, new Path(inputfile));
FileOutputFormat.setOutputPath(job, new Path(outputFile));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
|
Hbase 实战
这里主要记录Hbase shell里的一些常用指令
创建表
新建一个名为test的表,使其中包含一个名为data的列,表和列族属性都为默认值:
创建完成后,我们可以输入list来查看表是否创建成功
添加数据
我们来给上一关创建的test表的列data添加一些数据.使用put命令可以用来添加数据,使用get命令可以获取数据。
1
2
3
| put 'test','row1','data:1','value1'
put 'test','row2','data:2','value2'
get 'test','row1'
|
输入scan命令就可以查看所有的数据了
删除数据和表
删除整行数据:deleteall [表名],[行名称]
删除表需要先禁用、再删除。分为两步: