推荐系统与因果推断的结合是近几年来一个十分有趣的研究方向。本文提出了一种统一的推荐系统中的因果分析框架,可以将许多经典的推荐系统的研究问题归结到因果推断,并使用后者的理论进行分析。对个人而言,读这篇论文的收获主要在于了解推荐系统中的常见因果问题,以及因果方法论。
【目录】
研究简介
近年来,基于因果推断的推荐系统 (RS) 已经在学术界和工业界得到了广泛关注。然而现有的工作缺乏一个统一的因果分析框架。为此,作者广泛调研了因果推断方法在推荐系统任务中的应用。随后,作者提出了一种新的因果分析框架,通过推荐系统中对于因果分析假设的违反情况归结前者中的问题类型。随后,本文形式化了推荐系统中许多现有的去偏(debiasing)和预测(prediction)任务,并且分别总结了基于统计的和基于机器学习的因果估计方法。
推荐系统中的热点问题
- 下列推荐系统中的研究问题均能归结到因果问题
- post-view click-through rate prediction (后视CTR预估):给定用户历史行为数据,预测其点击商品概率
- post-click conversion rate prediction (后点击转化率预估):给定用户历史点击数据,预测其下单商品概率
- uplift modeling(增量预测):预测用户被展示广告后购买意愿的增量
现有的推荐系统+因果推断研究的不足
缺乏一个统一的应用于推荐系统的因果分析框架. 原因:
- 现有的RS中的因果方法,缺乏一个清晰的数学形式化表征
- 研究对象是什么
- 研究场景是什么
- 技术点是什么
- 基于什么理论假设
- RS数据中十分常见的偏差(bias),缺乏形式化的因果领域的定义
- 对于偏差本身的定义的缺乏,导致现有的去偏(debiasing)方面的工作难以在因果推断的框架下作分析
本文的主要贡献
- 明确了如何定义、重建、估计RS中的因果估计值(causal estimand)
- 提出了一个基于潜在得分模型(potential outcome framework,一个经典的因果推断框架)的因果分析框架,用于将RS中的多种偏差(biases)进行分类和形式化定义
- 揭示了RS的去偏方法中蕴含的核心的理论假设,并且据此将偏差分为选择偏差(selection bias)和混淆偏差(confounding bias)
- 将上述因果分析框架应用于RS中的去偏及预测任务中,总结了基于统计的和基于机器学习的因果估计方法
- 讨论并展望了因果推荐的未来的研究方向(挖坑)
推荐系统中的因果分析框架
本文提出的统一的因果分析框架,其工作流程分为三步:
- 定义研究问题的因果估计量(明确研究对象)
- 讨论给定观测数据时该因果估计量的可恢复性(明确能否找到该对象的真实值)
- 建立模型,获得该统计量的一致估计(一致估计:总能获得与真实(但不可见)值相同的估计结果)
该框架如下图所示。
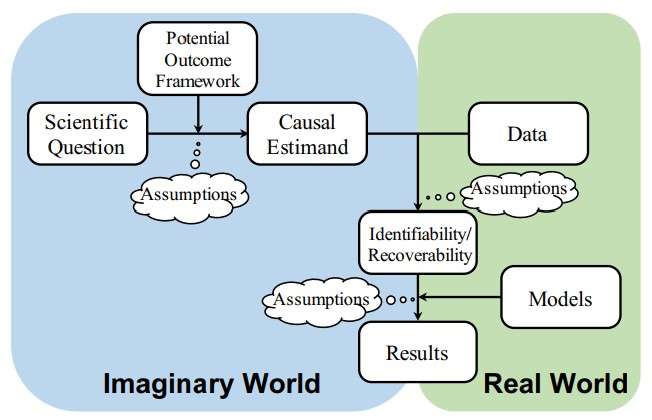
潜在得分、因果估计量
本文中使用的概念与数学符号:
- unit(单元): 因果推断中不可分的基本对象. 在RS中,一个unit可以是一个用户、一个商品,或者一个<用户,商品>的组合
: 处理操作(treatment) : 结果变量(outcome),指处理操作产生的效果 : unit的属性或者特征向量(feature embedding)
定义1(潜在得分). 潜在得分
假设1(稳定单元处理值假设,SUTVA). a. 处理操作只有一个版本,且尤其产生的处理组和对应的对照组有且只有一个版本. b. 一个unit的潜在得分不受其他任何unit的处理操作影响
需要注意,SUTVA的成立是潜在得分的良定义的必要条件。然而SUTVA的两项,在RS均有可能被违反:
- RS中的位置偏差(position bias)违反了SUTVA(a): 假设unit=<用户u,商品i>,t=1表示商品被曝光,t=0表示商品不被曝光。则点击行为
不仅依赖于处理操作 ,还依赖于商品被曝光时的位置。曝光位置越靠前,点击率越高。 - RS中的从众偏差(conformity bias)违反了SUTVA(b): 由于群组(group)中用户间的社交的存在,用户很可能对商品作出与其他组内用户相似的评价(人云亦云),即一个用户的评价值(潜在得分)会影响另一个用户的评价值(潜在得分)
可恢复性:因果估计量的一致估计
定义2(因果估计量). 因果估计量是处理操作、单元的特征、潜在得分的联合分布的函数,为从数据中解答研究问题提供充组的帮助
需要注意的是,因果估计量的定义是与被真实收集到的数据以及RS模型无关的。个人理解,因果估计量即因果角度的“用户兴趣”。因果估计量可以看作一种随机变量,是可以被估计的。从因果角度,我们感兴趣的是它是否能被恢复。后者的定义如下:
定义3(因果估计量的可恢复性):给定数据生成过程的所有假设,以及处理操作、单元的特征、潜在得分的联合分布。则称因果估计量
简而言之,如果因果估计量能够被一致估计,那么它就是可恢复的。
与可恢复性相关的理论假设
假设2(结果变量的一致性). $Y(t)=\sum_{t\in T}I(t=t)Y
简而言之,对于任意一个单元
假设3(处理操作的正可能性)
简而言之,无论对于哪种用户,任何处理操作都有可能发生. 在RS中,曝光偏差(exposure bias)违反了这一假设:一个用户只被曝光了一部分特定的商品,因此剩下的商品的处理操作的概率为0,违反了该假设。
假设4(条件可交换性).
该假设表明,X阻断了所有T和Y之间的后门路径(如果删去用户特征X,则处理操作与结果变量是相互独立的)。
假设5(随机采样).
假设5表明,观测数据(如观测到的用户点击数据)的分布能够代表总体的分布。
推荐系统中的选择偏差与混淆偏差
- 在这一节中,作者将推荐系统中常见的偏差分类为选择偏差和混淆偏差两种。按本文的逻辑,推荐系统中的任何偏差都可以归类为此二者之一。下面给出具体定义
定义4(选择偏差,selection bias). 选择偏差表示观测数据的分布不能代表总体数据的分布,即假设5的违反:
例1:推荐系统模型倾向于过滤掉低评分商品,只推荐高评分商品给用户。由于从目标用户角度看到的商品分布不能代表总体分布(低评分商品看不见),因此产生了选择偏差,是为模型选择偏差(model selection bias)。
例2:用户在打分时,更倾向于给他们喜欢的商品打分,很少给他们不喜欢的商品打分(因此被曝光却未被打分的商品,有可能是本来应该被打低分的商品),因此产生了选择偏差,是为用户自选择偏差(user self-selection bias)。
定义5(混淆偏差,confounding bias). 混淆偏差表示由于协变量(同时影响T和Y)的存在,处理操作变量T和结果变量Y存在关联。这通常会导致:
定义5导致的结果比较绕。个人理解:由全期望公式可得,
例3(经典因果案例):在一个超市中,啤酒和纸尿裤的销售量是正相关的。但如果提高啤酒的进货量和曝光率,并不能帮助提高纸尿裤的销量——因为存在同时指向二者的协变量(许多青年男性购物时喜欢买啤酒,同时买纸尿裤给家里的婴儿),而非“购买啤酒”与“购买纸尿裤”之间存在因果关系。
将本文的因果分析框架应用于推荐任务
- 在这一节,作者给出了处理操作结果的定义,给出了6个推荐系统场景下的因果分析框架的应用(Section 5.1-5.6),并在 5.7 总结了现有的因果去偏方法论(Causal Debiasing Methodologies)。此博客重点在于处理操作结果的定义(因为后面的案例分析均是该定义的运用),5.1-5.7节可以直接看原文。
数学符号.令
定义5 通用处理结果. 对于一般的处理操作变量定义域
定义6 二元处理结果. 对于二元处理操作变量定义域
上述处理结果都是上文中提到的推荐系统中十分重要而因果估计量,亦即测量目标。
因果推荐的未来研究方向
在这一节,作者展望了因果推荐中潜在的有价值的研究方向,亦即可挖的坑。
- 数据融合(Data Fusion). 现实推荐场景中常常包含两类数据:大型有偏数据集(来自于观测数据)和小型无偏数据集(来自于实验)。这一方向的工作中心在于使用小数据集上的无偏性指导大数据集上的推荐策略,即取长补短、数据融合。
- 序列推荐(Sequential Recommendation). 这一方向的工作中心在于,将因果分析方法应用于用户购买商品行为序列中(例如购买手机和购买手机壳是否存在因果性),旨在通过此方法捕捉用户兴趣的动态变化,从而实现更加精准的推荐。
- 推荐系统的公平性. 略,相关研究论文很多,可自行阅读(dblp搜索“fairness recommendation”)。
- 干扰行为. 这里常指在用户社交网络中,用户会干扰/影响彼此的购买行为(人云亦云),即对上文中SUTVA假设的违反。现有的因果推荐方法对这一问题研究较少。