个性化学习者能力建模全新范式。

论文标题:Towards the Identifiability and Explainability for Personalized Learner Modeling: An Inductive Paradigm
作者:Jiatong Li, Qi Liu, Fei Wang, Jiayu Liu, Zhenya Huang, Fangzhou Yao, Linbo Zhu, Yu Su
作者单位:中国科学技术大学
论文链接:https://arxiv.org/abs/2309.00300
论文录用:The Web Conference 2024 Main Conference (Research Tracks)
作者主页:https://cslijt.github.io/
论文摘要
基于认知诊断(CD)的个性化学习者建模是许多网络学习服务的一项基础而重要的任务,它旨在通过从行为数据中诊断学习者的特征来建模学习者的认知状态。现有的认知诊断模型(CDMs)遵循认知状态-答题响应范式,将学习者认知状态和题目参数视为可训练的嵌入,并通过学习者得分预测来学习它们。然而,我们注意到这种范式不可避免地导致学习者建模的不可识别性,并导致可解释性过拟合问题,这不利于学习者认知状态的量化和网络学习服务的质量。为了解决这些问题,我们提出了一个可识别的认知诊断框架(ID-CDF),该框架基于一种全新的答题响应-认知状态-答题响应范式,该范式受到编码器-解码器模型的启发。具体而言,我们首先设计了ID-CDF的诊断模块,该模块利用归纳学习消除模型优化中的参数随机性,以确保学习者能力建模结果的可识别性,并捕获总体响应数据分布与认知状态之间的单调性,以防止可解释性过拟合。接下来,我们提出了一个灵活的ID-CDF预测模块,以保证诊断结果的准确性。我们进一步提出了一个ID-CDF的实现,即ID-CDM,以说明其可用性。在四个具有不同特征的真实数据集上进行的大量实验表明,ID-CDF可以有效解决上述研究问题,同时不失诊断结果准确性。
背景介绍
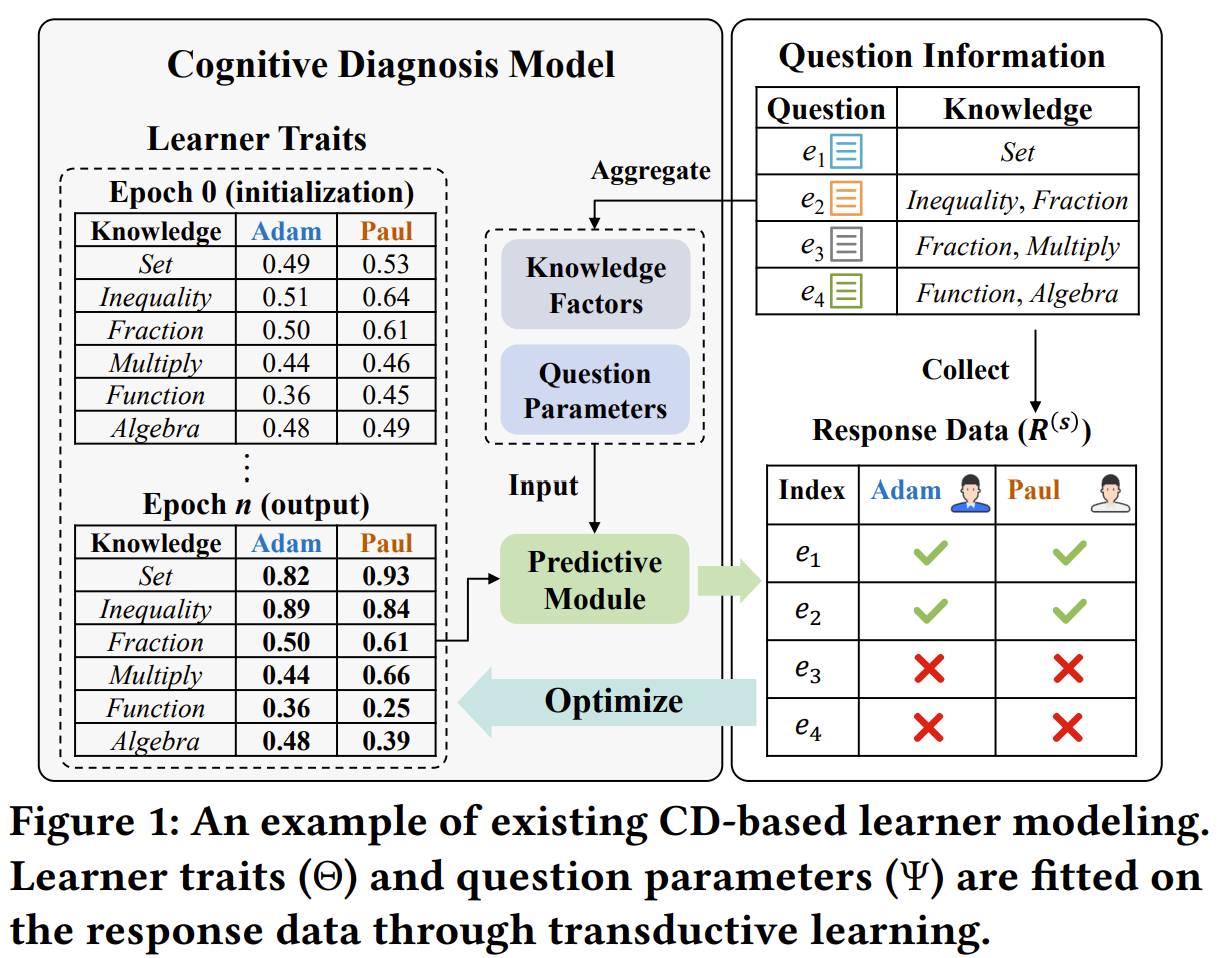
在各种Web学习应用(如在线学习平台、在线自适应测试)中,基于认知诊断(cognitive diagnosis, CD)的个性化学习者能力建模,是一项重要的基础任务。该任务的目标是从学习者的历史行为数据(绝大部分情况下,是答题得分记录)中诊断出学习者的认知状态(如对学科知识点的掌握水平)。诊断结果作为认知诊断模型(cognitive diagnosis model, CDM)的输出,一方面可以直接提供给学习者用户,作为其近期学习状态的反馈,另一方面可以作为用户特征(embedding),提供给下游任务挖掘进一步用途,如计算自适应测试(computerized adaptive testing, CAT)、习题推荐(item recommendation)等。需要注意的是,这里的“学习者”是指广义上的所有需要通过学习和测试过程积累知识的个体(如职业资格考试备考者、大学生),不仅仅是K-12教育中的学生。
研究动机
从研究现状看,现有的基于深度学习的学习者能力建模认知诊断模型(cdm)都遵循“能力水平->响应”范式(proficiency-response paradigm),即把学习者认知状态以及试题特征视作可以从数据中学习的embedding,并通过预测答题得分->计算损失函数->反向传播的方式来优化embedding,从而得到预测结果。这一范式与推荐系统中的双塔模型极为类似。即便是不基于深度学习的传统认知诊断模型如DINA(Deterministic Input, Noisy “And” gate model),“能力水平->响应结果”这一逻辑依然保持。倒不如说,基于深度学习的CDM的proficiency-response paradigm,就是从传统CDM这里一脉相承的。前者通过神经网络强大的函数拟合能力,能够准确地预测学习者在试题上的答题得分。然而,这一范式容易导致两个难以解决的问题,一是无法保持诊断结果的可识别性,二是导致诊断结果可解释性的过拟合。
其中,可识别性是指,给定交互函数(CDM的答题得分预测函数)
另一个问题,可解释性过拟合,是指诊断结果只在训练数据上有较好的可解释性,在测试数据上却难以解释。这一现象是我们首先通过实验观测到的。这里的“可解释性”是指教育测量层面的可解释,即诊断结果能够反映学习者真实认知状态的程度,需要通过“单调性假设”来维持,即学习者诊断结果随相关习题得分单调递增。可解释性对于学习者能力建模是至关重要的,毕竟诊断结果会直接输出给学习者作为其学习情况反馈,需要令其信服,不像推荐系统中服务提供方只关注推荐效果,如CTR。然而传统范式中,学习者能力是从训练集得分中一个一个“优化”出来的,天然地会导致其单调性指标在训练集上很高(虚高),在验证集和测试集上很拉跨。相关研究中的可解释性指标也都是在训练集上计算的。因为人们不需要通过可解释性“预测”什么,只关注其“在已观测的数据上是否分布合理”。然而,这与可解释性的初衷,即“由有限的已知数据推断隐藏在背后的真实能力”,是相悖的。
从研究目标看,我们认为学习者能力建模这一任务本身,更应该关注由数据到认知状态的诊断过程,而非由认知状态到数据的预测过程。进一步讲,一个具有实际应用价值的学习者能力建模服务,应当更加关注诊断结果本身的质量,而非答题预测精度,并且整个诊断过程是直接的、端到端的。当一个在线学习者用户想测评其认知状态时,他只需要输入答题数据,得到输出的诊断结果。不幸的是,现有的CDM都做不到这一点。现有的CDM由于是基于参数优化来估计学习者能力结果的,因此每当一个学习者用户想要测评认知状态时,他必须将自己的答题数据放入全量答题数据中(如果之前有10,000名用户,那么现在就有10,001个用户),重新训练一遍整个模型。注意,冻结其他参数而只训练自己的能力参数这是不可取的,因为容易导致严重的过拟合,而且诊断结果完全不可识别。因此,在实际应用中,现有的CDM也是难以部署的,更多停留在实验室阶段。
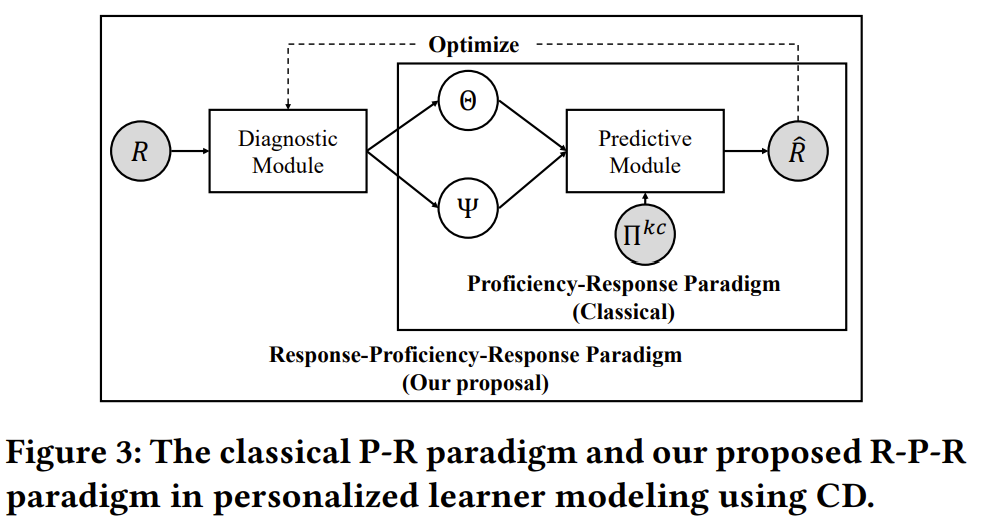
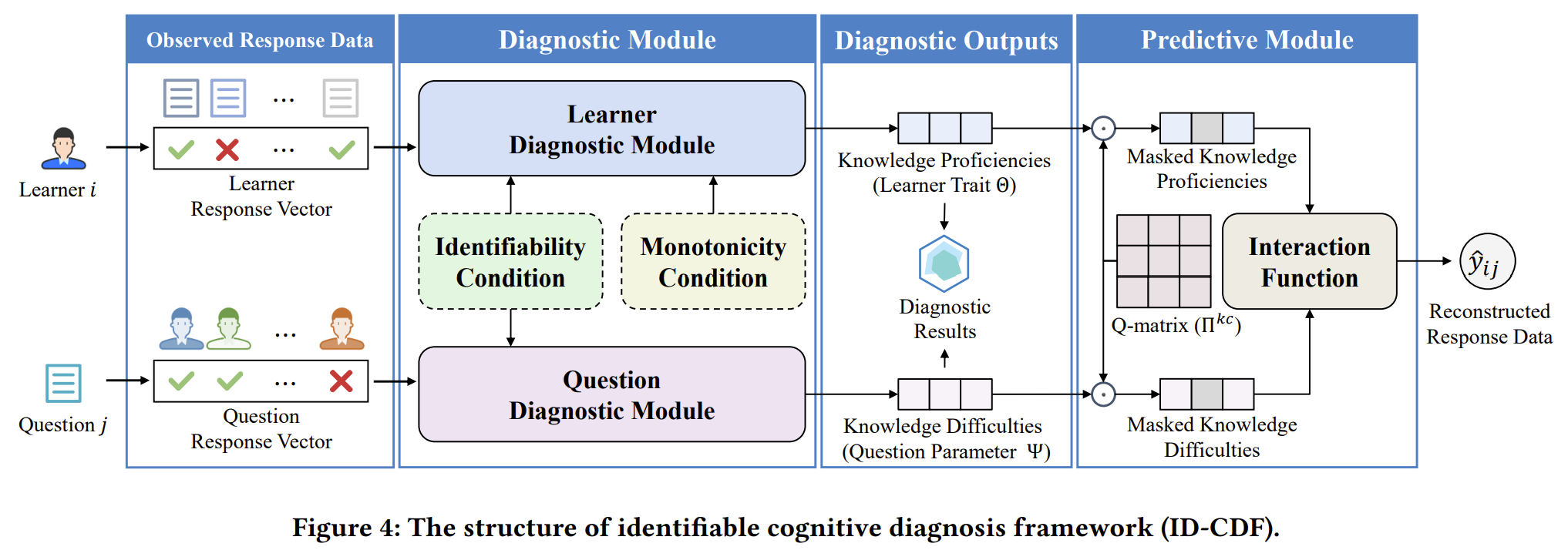
因此,为了解决上述的棘手问题,我们首先开创了一种全新的学习者能力建模范式,Proficiency-response-proficiency paradigm,如Figure 3所示。基于这一新范式,我们提出了一种可识别的认知诊断框架ID-CDF,如Figure 4所示。在这一框架中,学习者认知状态和试题特征不再通过参数优化学习得到,而是通过诊断模块Diagnostic Module一步得到。
ID-CDF:通用的可识别认知诊断框架
如 Figure 4 所示,ID-CDF这一框架包含两大模块:诊断模块(Diagnostic Module)和预测模块(Predictive Module)。
诊断模块(Diagnostic Module)
诊断模块的目的是通过归纳式学习(inductive learning),彻底解决现有学习者能力建模方法的不可识别问题,并通过额外引入的约束机制(可定制,可拓展)来满足诊断结果的可解释性,并且归纳式学习本身能够有效缓解可解释性过拟合问题。具体而言,在这一模块中,学习者和试题的答题数据(本文实现中为0-1的答题得分)首先编码为向量。设有N名学生和M道试题,那么每一名学生的答题数据向量是M维的,每一维度表示在该题的得分(1 = 答对;0 = 未做; -1 = 答错);类似地,每一道试题的答题数据向量是N维的。上述编码方式可如下公式所示形式化地表示:
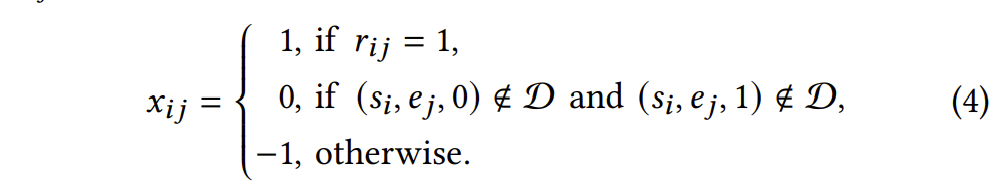
接下来,诊断模块通过如下形式的诊断函数从答题数据中(归纳式地)直接计算出学习者和试题的诊断结果。其中
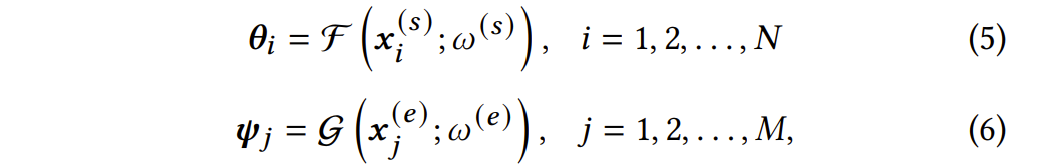
- 可识别性条件(Identifiability condition): 一个诊断函数满足可识别性条件,当且仅当诊断结果是完全由可观测量决定的。换言之,该函数的计算过程不允许存在任何可能导致诊断结果改变的外部的不可观测量。
- 这一条件可以概括为,“所见即所得”。例如,如果学习者答题数据中仅有答题得分,那么可识别的诊断函数必须保证诊断结果是完全由答题得分决定的,不能存在随机因素或不可见的学习者个人因素(如学习者ID)。
- 单调性条件(Monotonicity condition): 一个学习者诊断函数满足单调性条件,当且仅当诊断结果相对于输入的任意一个维度是单调递增的。
- 单调性条件源于心理测量学中基础但重要的的“单调性假设”,即学习者的真实能力水平是随其正答概率单调递增的。由于学习者的真实能力是未知的、不可观测的,因此在单调性假设成立的前提下,通过单调性条件来保证估计出的学习者能力诊断结果的可解释性。
上述两个条件是解决本文研究问题的钥匙,也是ID-CDF对诊断函数设计的唯二约束。在满足上述两个条件的前提下,ID-CDF允许并鼓励使用者定义自己的诊断函数,以满足不同场景的需求。本文中为验证这一模块的准确性,使用了全连接神经网络来定义。使用者也可考虑使用CNN、RNN或其他定义方式,设计符合自己需求的诊断函数。
预测模块(Predictive Module)
预测模块的目的是通过利用诊断结果重建可观测量(答题数据),以保证诊断结果的准确性及其在下游任务中的潜力。ID-CDF的诊断模块就是目前已有的大多数认知诊断模型(CDM)的本体。例如DINA、IRT、MIRT、NCDM,均与ID-CDF的预测模块同构。在ID-CDF中,预测模块的本质是一个交互函数(interaction function),该函数通过模拟学习者调动自身认知状态以解决题目的过程,从诊断结果中重建答题数据。如下所示:
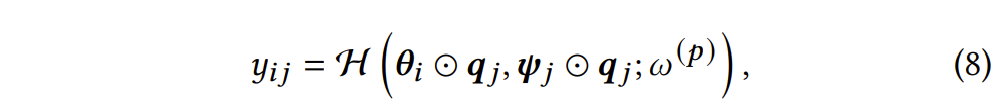
其中
损失函数
由于答题数据的重建结果是概率化的,因此使用交叉熵作为损失函数: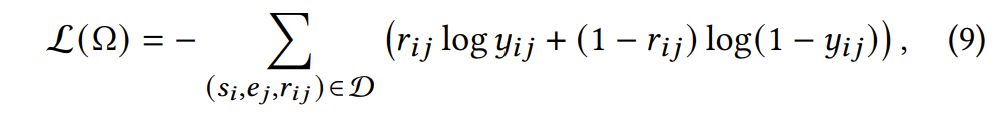
ID-CDM:ID-CDF的一种简洁实现
ID-CDM的提出目的,是作为ID-CDF的一种简洁实现,在实验中验证ID-CDF的有效性。
诊断模块的实现
在ID-CDM中,学习者诊断函数通过一个单调双层全连接神经网络实现:
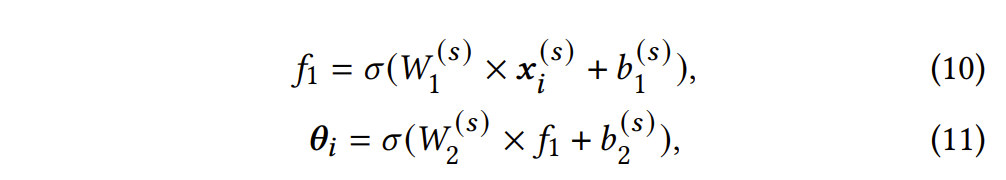
同时,试题诊断函数通过一个三层全连接神经网络实现:
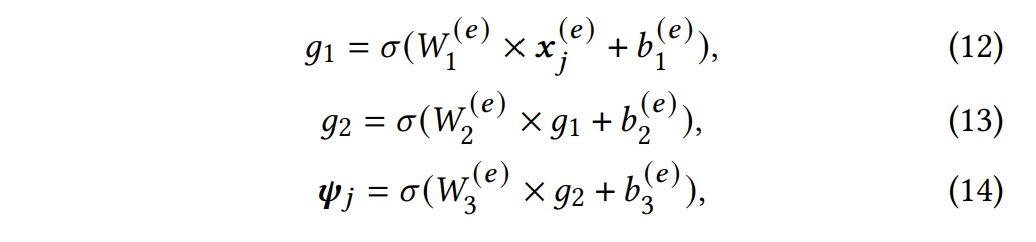
预测模块的实现
ID-CDM中,预测模块首先通过一个降维操作,将高维稀疏的诊断结果(注意,只关注那些被试题考察的知识点维度)压缩为低维高信息密度的诊断结果隐向量:
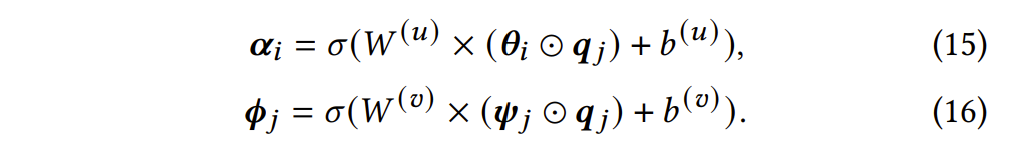
然后,再通过一个三层神经网络重建可观测量(答题得分):
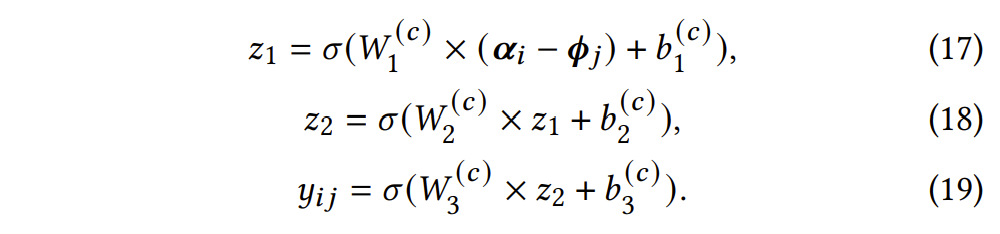
以上就是ID-CDM的实现。
实验部分
研究问题
- RQ1:ID-CDM诊断结果的可识别性如何?
- RQ2:ID-CDM诊断结果的可解释性如何?
- RQ3:ID-CDM诊断结果能否精准反映学习者的真实答题表现?
- RQ4:(由不同诊断模型给出的)学习者的诊断结果与其答题表现有何统计关联性?
为回答上述问题,我们设计了四个不同的实验,在四个具有不同特征的数据集上验证ID-CDM的有效性。数据集信息可见于原始论文。
可识别性评估(RQ1)
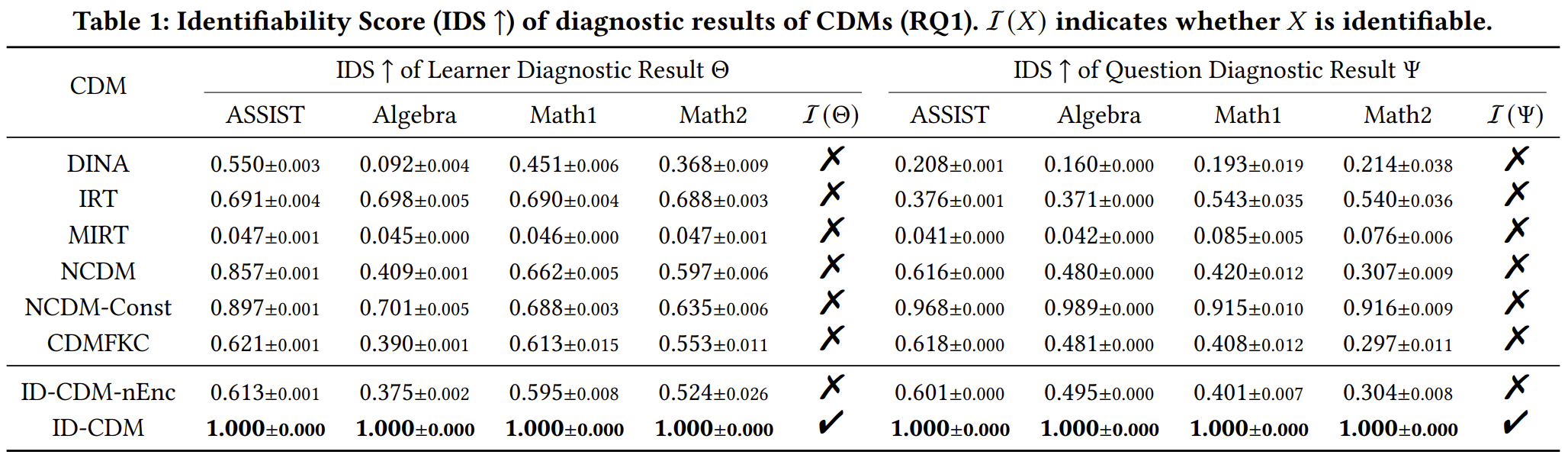
针对这一问题,我们提出一种名为可识别性得分(Identifiability Score, IDS)的评价指标。该指标在增强数据集上检测具有相同可观测量的学习者或试题的诊断结果相似性以评价可识别性。IDS介于0和1之间,越接近1,则诊断结果的平均可识别性越强。当且仅当IDS = 1.0,全体诊断结果是严格可识别的。
如Table 1所示,我们计算了ID-CDM和诊断模型baseline各自的IDS。ID-CDM的诊断结果是所有结果中唯一可识别的。此外,ID-CDM-nEnc表示去掉诊断模块的ID-CDM,因此牺牲了可识别性条件,是用于验证可识别性条件有效性的消融实验。NCDM-Const表示使用常数初始化NCDM的诊断结果,以观察这种经典的去随机化方式能否解决传统CDM的不可识别问题。结果表明,虽然NCDM-Const的IDS相对于NCDM有一定提升,但仍然未能彻底解决不可识别问题。因此,在上述方法中,ID-CDM是唯一能够彻底解决不可识别问题的方案。
可解释性评估(RQ2)
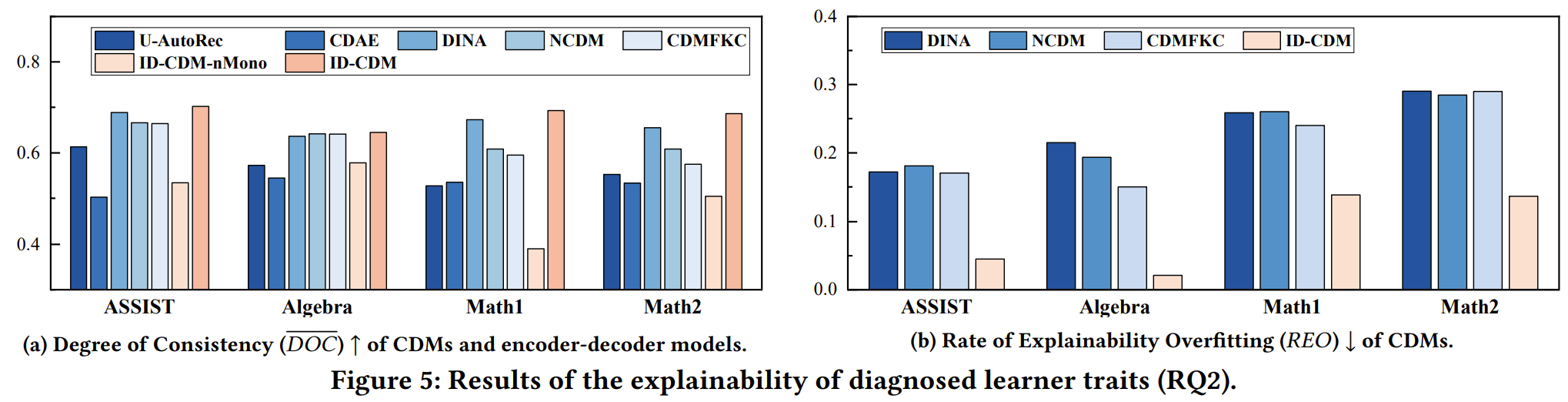
针对可解释性评估问题,我们提出两个指标以从不同角度测量诊断的可解释性:一致性程度(Degreement of Consistency, DOC)和可解释过拟合率(Rate of Explainability Overfitting, REO)。DOC介于0-1之间,测量诊断结果在测试集上的单调性程度,越高越好;REO通常介于0-1之间,测量诊断结果可解释性过拟合程度,越低越好。
如Figure 5所示,ID-CDM无论在DOC还是REO上都达到了SOTA。此外,ID-CDM-nMono是去掉了单调性约束的ID-CDM,是用于验证单调性约束有效性的消融实验。实验结果表明,ID-CDM的诊断结果具有良好的可解释性,并且有效缓解了诊断模型中存在的可解释性过拟合问题。
学习者得分预测(RQ3)
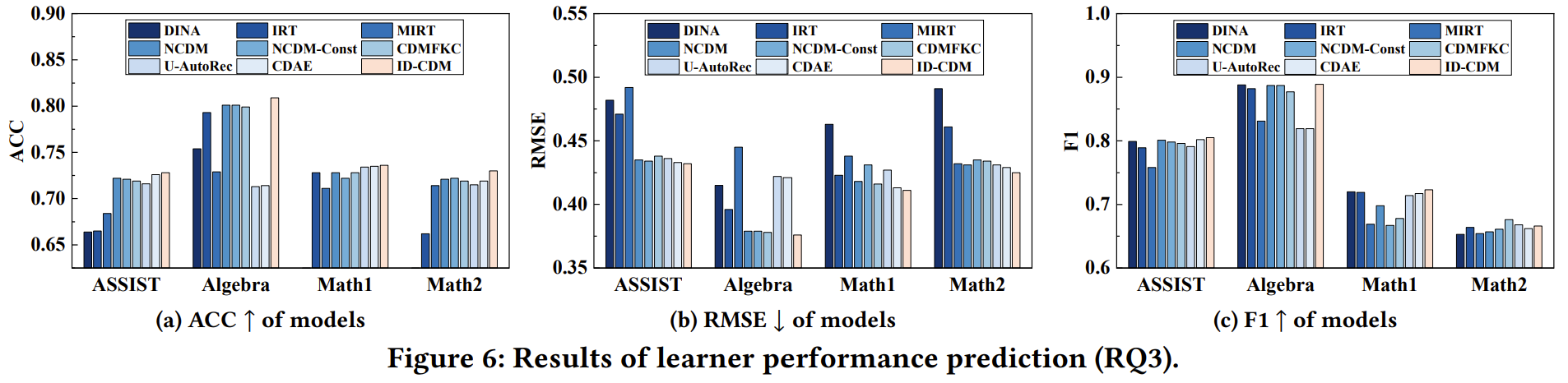
学习者得分预测既可以看作分类问题,也可以看作回归问题。因此我们使用Accuracy、F1 score、RMSE三个指标,全面评估答题得分预测的精度,以比较不同模型给出的诊断结果的准确性。由Figure 6可见,即便我们没有在得分预测精度方面为ID-CDM作任何增强,其预测精度相对于baseline中的SOTA仍然没有损失。这足以验证ID-CDM在诊断结果精准度方面的有效性。
诊断结果聚类(RQ4)
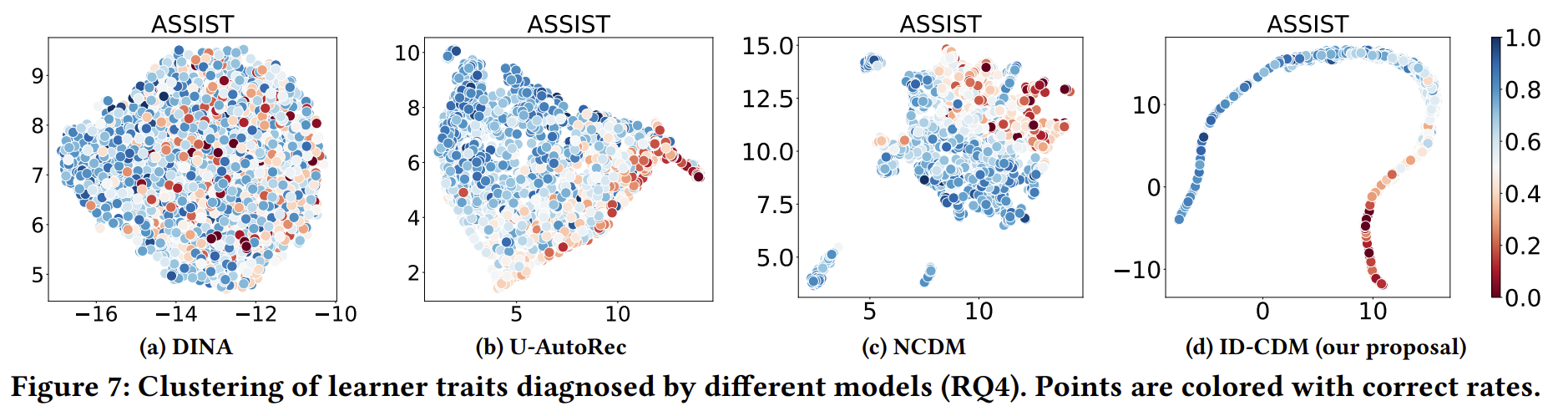
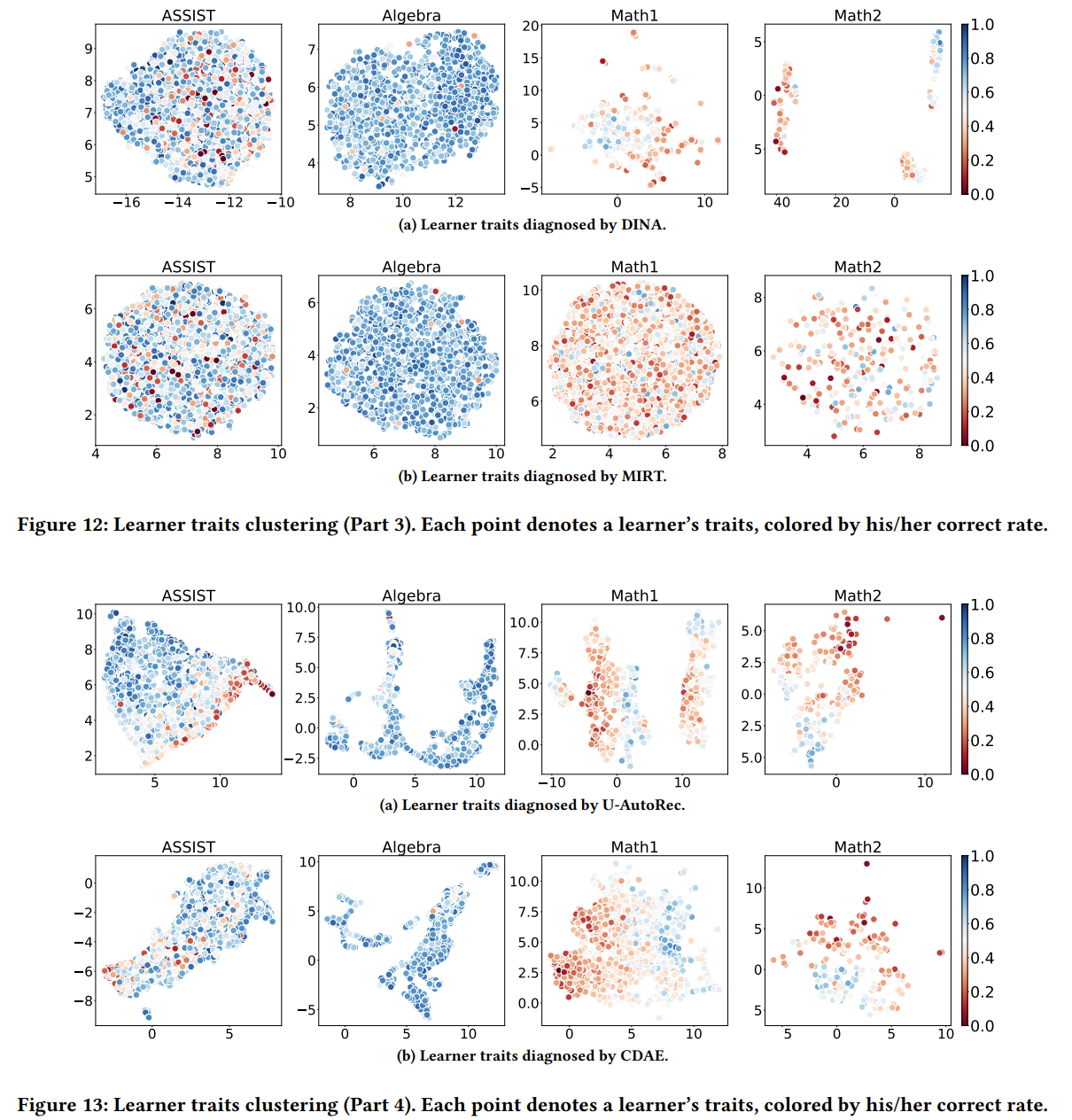
为探究诊断结果与答题得分表现之间的统计关联性,我们首先使用UMAP算法将高维的学习者能力降维至2维,再将每个学习者对应的点按照其答题得分率染色(得分率越高越偏蓝色,得分率越低越偏红色),再观察学习者能力点能否按照答题得分率很好地聚类。聚类效果越好,则诊断结果与答题表现之间的统计关联性越强,可解释性越好。
Figure 7 展示了正文中呈现的初步结果。其中ID-CDM的诊断结果可视化呈现条带状,且条带的延伸方向与得分率的变化方向一致,因此能够很好地按答题得分率聚类学习者。NCDM和U-AutoRec(经典的encoder-decoder用户建模模型)聚类效果也尚可,但相比ID-CDM的结果更松散。DINA的可视化中,各种得分率的学习者点则完全混杂在一起,无法聚类。上述结果说明了ID-CDM的诊断结果与答题得分表现之间有较强的统计关联性。这可以从流形的角度解释,可留给读者自行想象。
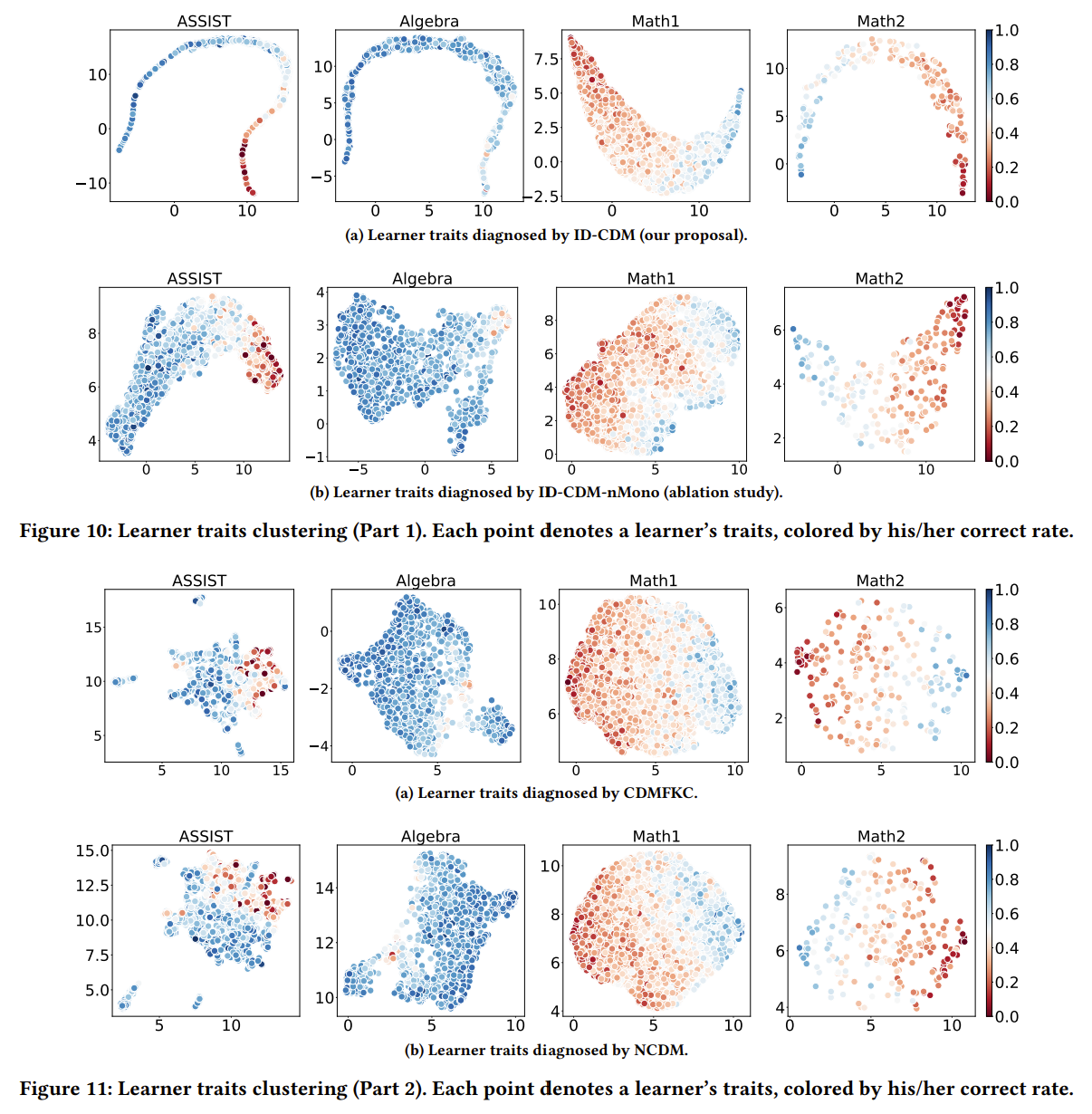
我们还在附录中进一步讨论了各种baseline对于学习者的聚类能力,以及ID-CDM的不同组件对其聚类能力的影响。我们主要阐述后者的直观结论:
- ID-CDM的诊断模块(新范式中的创新点)对于聚类的影响在于,其可以将聚类结果由圆形(如NCDM诊断结果可视化)变成条带形,延长条带的长度,在答题得分变化的“纵向”上增强诊断结果与之的统计关联性。
- ID-CDM的单调性约束对于聚类的影响在于,其可以缩短条带的宽度,在答题得分变化的“横向”上增强诊断结果与之的统计关联性(见ID-CDM-nMono诊断结果可视化)。换言之,具有相似答题得分率的学习者,也具有相似的诊断结果。这可以视作松弛版的可识别性。
结论
本文研究了基于认知诊断的学习者建模任务中普遍存在的不可识别性和可解释性过拟合问题,并提出了一个通用的可识别、可解释的认知诊断框架(ID-CDF)来解决这两个问题。具体来说,我们提出了一个新的答题响应-认知状态-答题响应(R-P-R)范式,从根本上解决这两个问题。基于此,我们提出了ID-CDF,它利用诊断模块从响应数据中获得可识别和可解释的诊断结果。然后,它使用预测模块对学习者和问题之间的复杂交互进行建模,以保证诊断结果的准确性。然后,我们提出ID-CDM作为ID-CDF的实现,以显示其可用性。最后,我们通过在四个真实数据集上的大量实验证明了ID-CDF的有效性。