基本概念;数据存储;数据表示
既包含概念性知识,也包含一些方法论
基本概念
- 数据库的定义:数据库是长期储存在计算机内、有组织的、可共享的大量数据的集合
- 数据库模式(Schema)的定义:数据库模式是数据库中全体数据的逻辑结构和特征的描述
- 数据库管理系统(DBMS):计算机程序的集合,用于创建和维护数据库。
- 位于OS和APP之间
- 总是基于某种数据类型
- 例子:MySQL, Oracle11g
- 数据库系统(DBS):在计算机系统中引入了数据库后的系统,即采用了数据库技术的计算机系统
数据存储
主要内容:
- 存储器结构
- 磁盘块存取时间(计算)
- 不同存储介质的差异
存储器结构
- 核心思想:层次化存储
- 寄存器-内存-磁盘-磁盘阵列-磁带-…
- 典型的磁盘结构
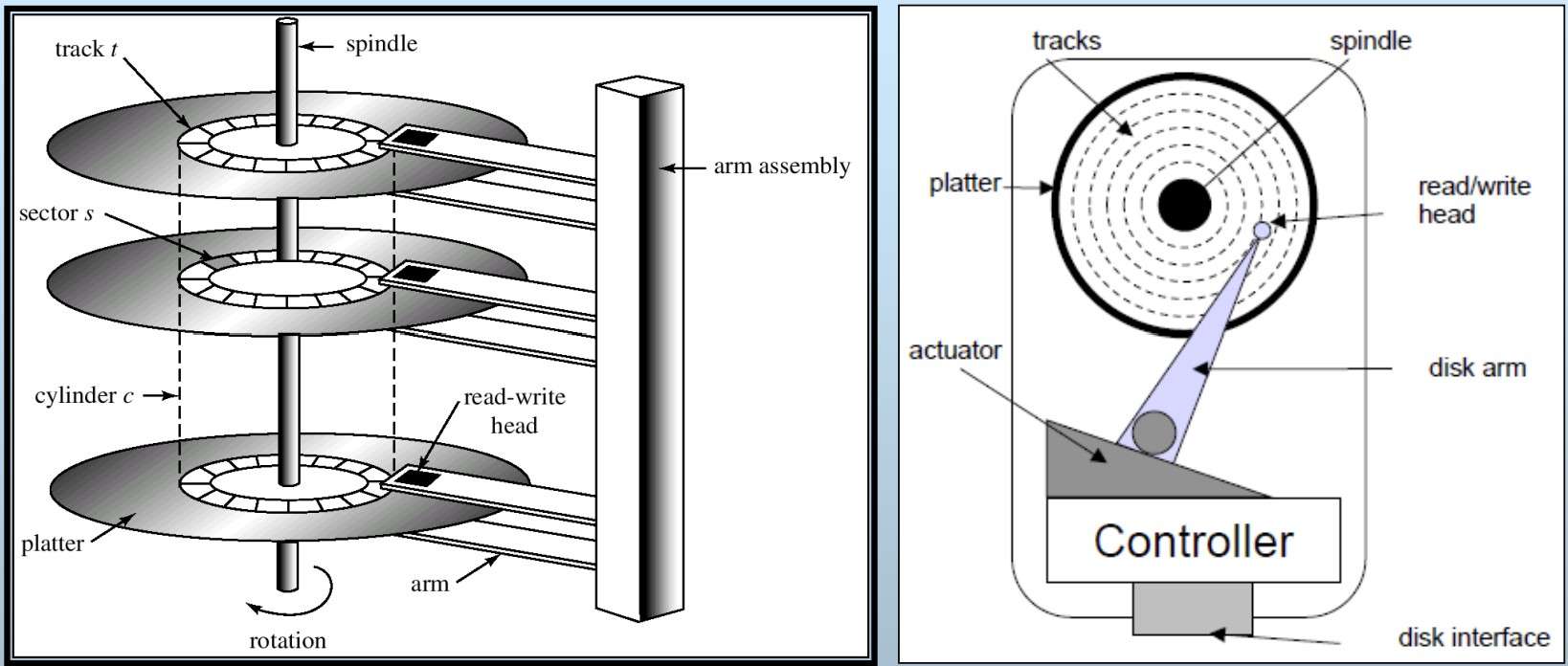
- 重要术语:盘片platter,盘面surface,磁头R/W head,磁道track,柱面cylinder,扇区sector
磁盘块存取时间
- 块(Block)是OS或DBMS进行磁盘数据存取的最小逻辑单元,由若干扇区组成
- 块是DBMS中数据存取的最小单元(逻辑)
- 扇区是磁盘中数据存储的最小单元(物理)
读块时间计算
- 在真实情境中,会要求计算“最优”、“平均”、“最坏”情况下的读块时间
一般在10ms-40ms之间 - R是磁盘转动到块的第一个扇区到达磁头所需的时间.
- 磁盘转速单位:RPM (Rotation / Min)
- 平均时间为旋转1/2周所费的时间
- e.g., 一个7200RPM的磁盘,平均旋转延迟
- T是块的扇区及其间隙旋转通过磁头所需的时间
- e.g., 磁道大约有100,000 Bytes,约10ms转一周,则每秒可从磁盘读取1000/10*100000
10MB. 一个4KB的块传输时间小于0.5ms
- e.g., 磁道大约有100,000 Bytes,约10ms转一周,则每秒可从磁盘读取1000/10*100000
- 其他延迟:
- CPU请求IO的时间
- 争用磁盘控制器时间
- 征用总线和主存的时间
- 典型情况:0(忽略不计)
- 如何读下一块:
- 在同一柱面上->
- 不在同一柱面上->
- 在同一柱面上->
写块时间计算
- 如果无需校验;则与读块相同
- 如果需要校验,则需要加上1次旋转时间和1次块传输时间
块修改
- 将块读入主存
- 在主存完成修改
- 将块重新写入磁盘
- 块地址=<物理设备号,柱面号,盘面号(或磁头号),扇区号>
不同存储介质优缺点对比
- 传统存储器件:磁盘、磁带等
- 新型存储器包括:闪存、相变存储器、磁阻式存储、电阻式存储器、忆阻器等. 共同特点:非易失性
- 优点:高存储密度、低功耗、无机械延迟、存取速度快、便携、抗震、低噪音
- 缺点:读写性能不对称、读写次数有限、可靠性不高
闪存(Flash Memory)
- 读写不对称(写慢读快)
- 写前擦除:异位更新、块擦除操作
- 寿命有限:块擦除次数有限
- 按页读写
- 按块擦除
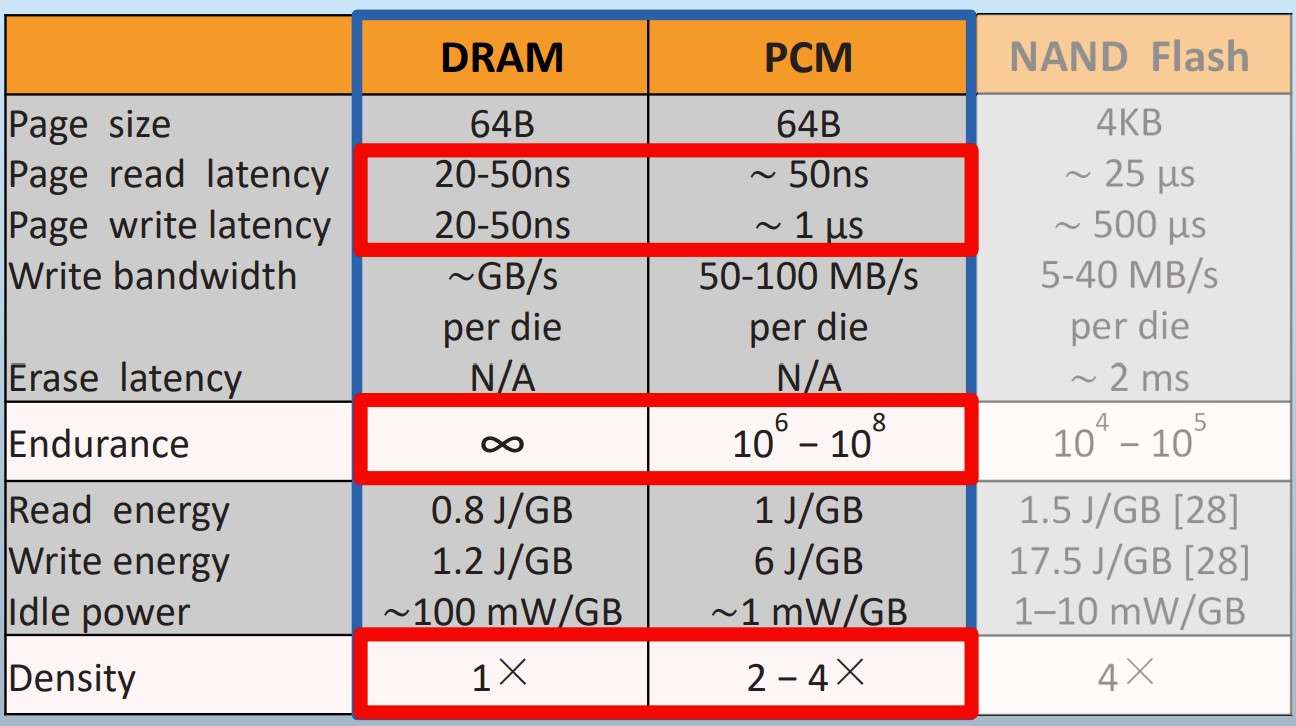
相变存储器(Phase Change Memory)
- 与传统介质和闪存的性能参数对比
数据表示
主要内容:
- 数据项的表示
- 记录的表示
- 记录在块中的组织
- 块在文件中的组织(链表式堆文件和目录式堆文件)
数据元素的表示层次:
数据项->记录->块->文件
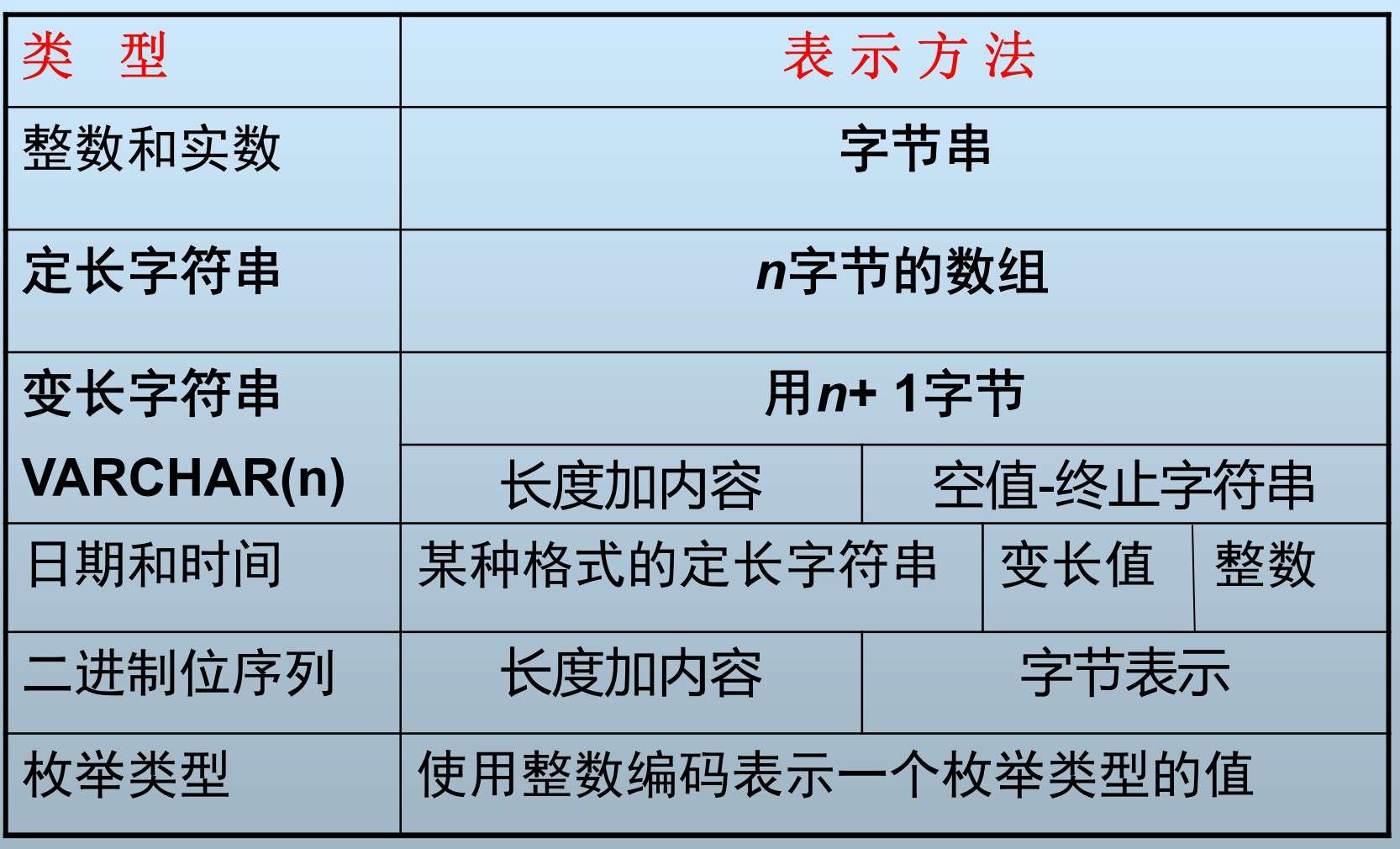
数据项的表示
- 数据项本质是字节序列,表示关系数据库中元组的属性值
- 数据项表示方法:SQL数据类型
- e.g., Integer (short),2 bytes, 16 bits
- SQL中的数据项表示总结
记录的表示
- 记录是数据项的集合
- 记录的类型
- 固定格式 vs. 可变格式
- 定长 vs. 变长
固定格式定长记录
- 所有记录具有相同的逻辑结构(模式)
- # fields
- Name of each field
- Type of each field
- Order in record
- offset of each field in the record
1 | -- SQL中固定格式定长记录的构造 |
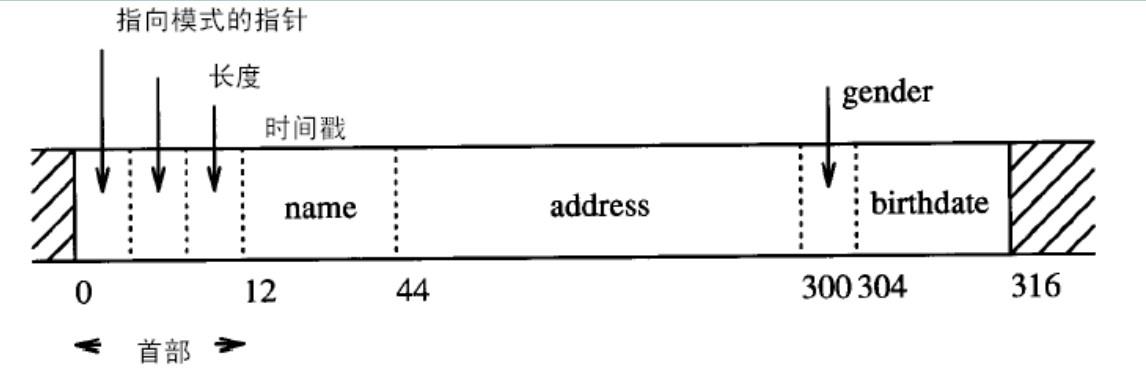
记录首部
- 在记录首部(Head)描述记录的信息
- 记录类型(模式信息)
- 记录长度
- 时间戳(用于并发控制)
- 其他信息
- 示例
可变格式记录
- 每个记录的格式不同
- 记录的格式存储于记录中
- 典型例子:Key-Value. Key与Value都以字节流存储,如:
1 | typedef struct{ |
- 优点
- 灵活的记录格式,适合“松散”记录,如病人的检验结果
- 适合处理重复字段
- 适合记录格式演变
- 缺点
- 标记存储方式空间代价高
- KV方式难以支持复杂查询
- 应用负担重且事务处理等实现困难
记录在块中的组织
- 定长记录:记录地址rid通常使用<块号,槽号>表示
- 变长记录:记录地址通过槽目录+<记录偏移量,长度>表示
块在文件中的组织
- 堆文件(Heap File)
- 最基本、最简单的文件结构
- 记录不以任何顺序排序
- 记录可能存放在物理不邻接的块上
- 插入容易,但查找和删除代价高
- 链表式堆文件组织
首块 <-> 数据块 <-> 数据块 <-> 数据块 -> 含空闲空间的块链表
- 目录式堆文件组织
[邻接数据块阵列(首块)] -> [邻接数据块阵列] -> [邻接数据块阵列] -> …
SQL Server的数据存储结构
- 数据存储的基本单位式是页。一页的大小是8KB
- 页地址:<文件号,页号>
- 数据行地址:<页地址,槽号>
- 扩展盘区:介于块和文件之间,一个扩展盘区是8个邻接的页(或64KB)
- SQL Server文件组织
- 主要数据文件(.mdf):指向数据库中文件的其他部分
- 次要数据文件(.ndf)
- 日志文件(.ldf)
- 数据文件的起始结构:PFS页,GAM页,SGAM页
- PFS:记录扩展盘区的哪些页已分配或可用,一个PFS记录约8,000页
- GAM:记录已分配的扩展盘区,每个元素是一个PFS
- SGAM:记录当前用作混合扩展盘区且至少有一个未使用的页
| 扩展盘区的当前使用情况 | GAM位设置 | SGAM位设置 |
|---|---|---|
| 可用,未使用 | 1 | 0 |
| 统一扩展盘区或已满的混合扩展盘区 | 0 | 0 |
| 有可用页的混合扩展盘区 | 0 | 1 |